Produit / Flux de données
Entonnoir en entrée — Canaux en sortie
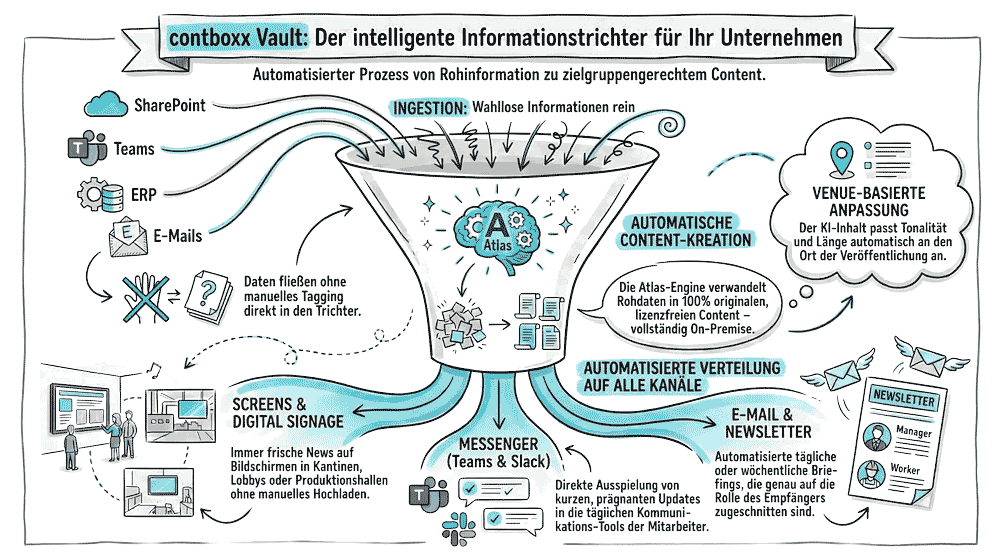
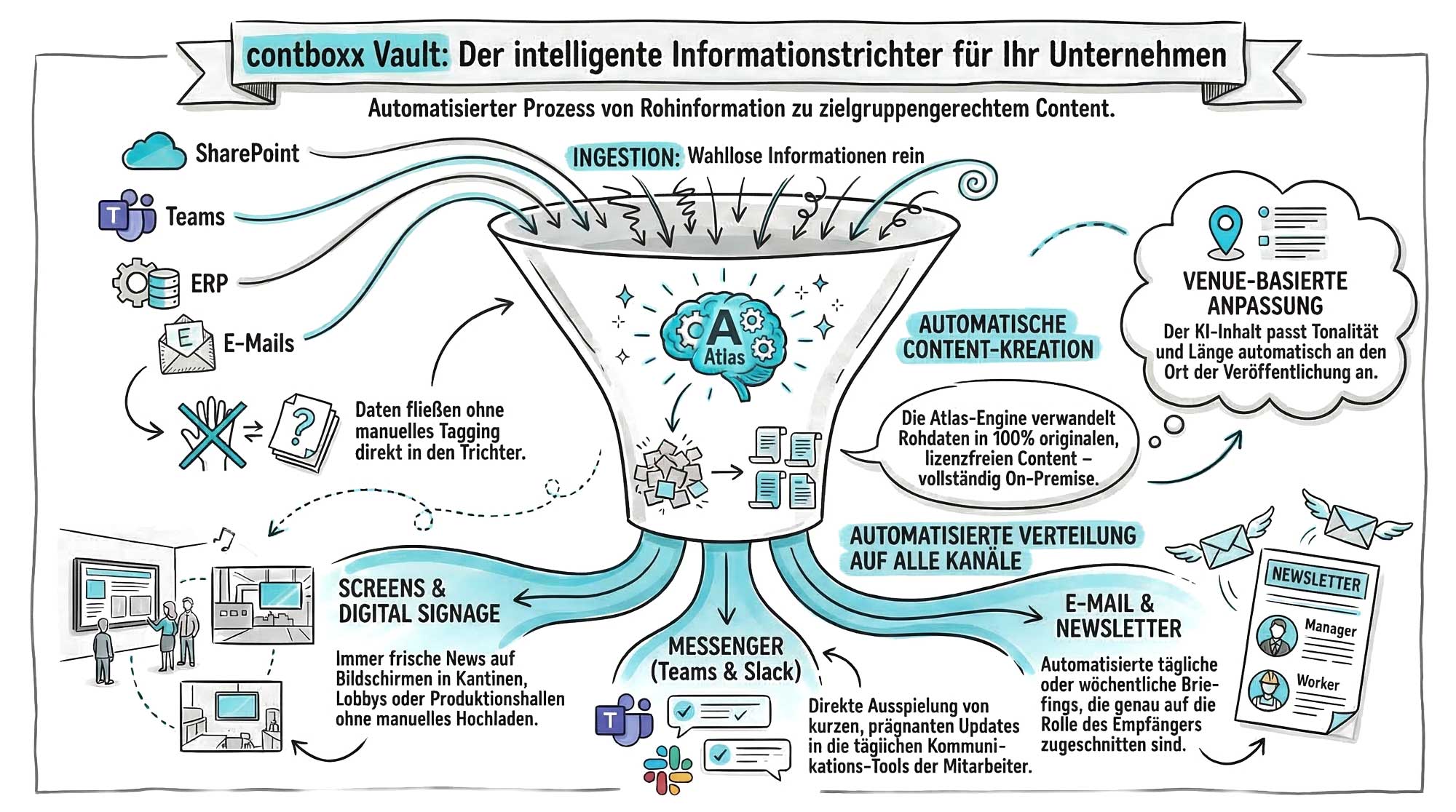
Zéro effort à l'ingestion. Impact maximum à la diffusion. Voici comment les informations circulent dans contboxx Vault.
Sources : D'où viennent les informations
Vault ingère les données de tous les systèmes — non catégorisées, non structurées, sans effort manuel. Il suffit de les introduire.
Systèmes documentaires
SharePoint, Confluence, Google Drive, Notion
Systèmes de fichiers
Lecteurs réseau (SMB/NFS), dossiers cloud, FTP/SFTP
Systèmes métier
SAP, Salesforce, HubSpot, ServiceNow
Communication
Email (IMAP), Slack, Microsoft Teams
Sources web
Flux RSS, HTML/sites web, pages intranet
Manuel
Téléchargement par glisser-déposer, ingestion API
L'entonnoir : Ce qui se passe à l'intérieur
Cinq étapes de traitement — entièrement automatiques, en secondes à minutes.
Détection et extraction
Détecter le format (PDF, DOCX, HTML, email ...), extraire le texte et les métadonnées, OCR pour les scans et documents image.
Compréhension du contenu
L'IA lit et comprend le contenu sémantiquement — pas seulement une recherche par mots-clés, mais une véritable compréhension du texte.
Structuration et classification
Attribution automatique aux thèmes, départements, types de documents. Des tags et catégories sont attribués.
Liaison et enrichissement
Créer des résumés, détecter les doublons, établir des références croisées, générer des traductions.
Indexation et mise à disposition
Préparation pour la recherche sémantique et distribution aux canaux de sortie configurés.
Canaux : Où les informations sont diffusées
Vault distribue le contenu préparé de manière ciblée vers tous les canaux — automatiquement, dans la langue et le ton appropriés.
Digital Signage
Écrans digital signage (HTML5), bornes d'information, écrans de salles de réunion, halls de production
Messagerie
Canaux Slack, Microsoft Teams, notifications automatiques
Newsletters internes, circulaires, modèles marketing, emails de synthèse
Flux et APIs
Flux RSS/Atom, notifications webhook, API REST